Python爬虫-scrapy中使用CrawlSpider进行全站数据爬取
目标:爬取豆瓣图书科普分类下的若干页图的书名。
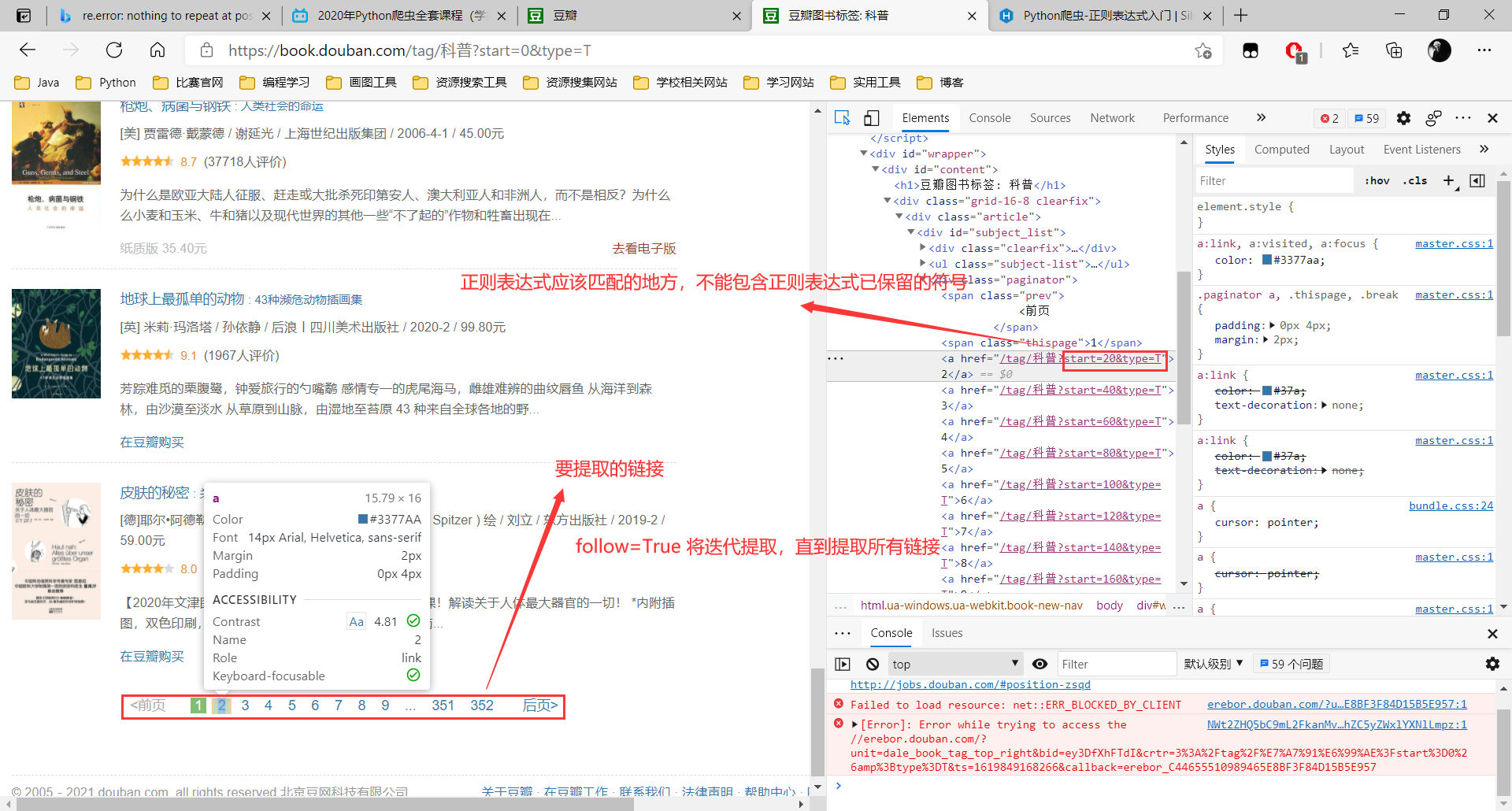
CrawlSpider:为Spider的一个子类,可以很方便地提取页面中的链接并对请求内容进行解析。
使用CrawlSpider:创建好scrapy工程后,输入scrapy genspider -t crawl CrawlSpiderName www.xxx.com。
使用CrawlSpider
前提:setting.py中设置好LOG_LEVEL,ROBOTSTXT_OBEY,DOWNLOADER_MIDDLEWARES,ITEM_PIPELINES。
介绍
LinkExtractor:链接提取器,可以将start_urls中的页面满足特定正则表达式的链接提取出来。
Rules:规则解析器。规则解析器由链接提取器创建,可以将链接提取器提取的链接交给callback指定的解析函数进行解析。Rules中的follow参数指定是否进行迭代提取,也就是是否在LinkExtractor提取出的链接所对应的页面中,继续应用rules进行解析。
Rules:
Which is a list of one (or more)
Rulebjects. EachRuleefines a certain behaviour for crawling the site. Rules objects are described below. If multiple rules match the same link, the first one will be used, according to the order they’re defined in this attribute.
链接提取器中的正则表达式只需要匹配链接的部分内容即可,完整的URL会被scrapy自动拼接上。(因为完整的链接可能包含正则表达式当中的符号,影响匹配规则。)
1 | import scrapy |
结果部分如下:
1 | ['疫苗竞赛', '网络是怎样连接的', '大图景', '世界观(原书第2版)', '万物皆数', '苏菲的世界', '人类大瘟疫', '性的进化', '半小时漫画经济学2: |
 微信
微信 支付宝
支付宝








